
Saqué una rola sin saber música: $16 USD, 2 días, AI
> No soy músico. No canto. No toco nada. Pero quería sacar una rola tumbada romántica que sonara como rola, no como meme. Te cuento todo el proceso, los costos exactos, los errores, y lo que aprendí.
No soy músico. No canto. No toco ningún instrumento. Pero quería sacar una rola tumbada romántica que sonara real, no a meme de internet. Te cuento todo: el stack, los costos exactos, los errores caros, y lo que NO recomiendo hacer.
Brief
La primera rola se llama "Mientras me mientas". Tumbado romántico, voz masculina, 88 BPM, key de A menor, 2 minutos y medio de "ya sé que me mientes y no me importa, mientras me mientas yo me quedo".
Subí el primer teaser a TikTok hoy. Este post es el making-of, con los números para que sepas qué esperar si te avientas algo así.
Stack completo
Tool | Costo mensual | Pa' qué |
|---|---|---|
Suno Pro | $8 USD | Generación de la rola (música + voz). Plan Pro da rights comerciales |
ElevenLabs Starter | $6 USD | Generación de imágenes (Nano Banana 2) y video (Kling O3) |
ElevenLabs add-on credits | $10 USD one-time | 40K créditos extra para terminar el experimento sin estrés |
Kdenlive | gratis | Edición final del teaser |
Whisper + librosa + Demucs (local) | gratis | Análisis de referencias musicales |
ComfyUI + SDXL local | gratis | Generación de escenarios (NO de personajes) |
Total invertido: $24 USD ($8 Suno + $6 ElevenLabs + $10 add-on creds). Todo lo demás corre local en mi máquina.
Paso 1: Ingeniería inversa - entender el género sin ser experto
No tenía idea de cómo se construye un tumbado romántico. Pero sí tengo Linux y herramientas. La estrategia: agarrar 2-3 rolas que me gustaran del género, descomponerlas técnicamente, y armar un brief informado para Suno.
Las herramientas:
yt-dlp- descargar el audio de YouTube como mp3librosa(Python) - analizar BPM, tonalidad, dinámica, instrumentaciónwhisper.cpp(large-v3-turbo) - transcribir las letrasDemucs- separar la rola en stems (voz, batería, bajo, otros)
Con eso obtengo de cada referencia:
BPM exacto
Tonalidad (key) con corr de Krumhansl-Schmuckler
RMS (qué tan compreso suena)
Spectral centroid (qué tan brillante)
Zero crossing rate (qué tan orgánico vs digital)
Letras completas con timestamps
Para "Mientras me mientas" usé como referencia rolas tumbadas de Linzae Lir: 88-92 BPM, A minor, voz masculina con autotune sutil, requinto + tarola + bajo de tuba programado. Eso me lo da el análisis en 30 segundos.
Y descubrí algo importante para el roadmap de Tlatol: dentro del tumbado hay sub-géneros con audiencias distintas. Hay tumbado tradicional (urban, populacho) y tumbado fifi (acústico-poético, Mon Laferte audience). Dos mercados disjuntos bajo el mismo paraguas.
Paso 2: Suno - prompt informado vs prompt random
La diferencia entre "le digo a Suno 'una rola tumbada triste'" y "le doy un brief técnico con BPM, key, instrumentación, vibe vocal, referencias" es la diferencia entre "esto suena a meme de Twitch" y "esto suena a algo que podría estar en una playlist real".
El brief que le pasé tenía:
BPM exacto
Key específico
Instrumentación detallada (qué requinto, qué tipo de tarola, qué bass)
Estilo vocal (autotune sutil, no excesivo, voz cálida masculina, mid-range)
Mood (melancólico pero no llorón, conviction de "ya lo acepté")
Referencias verbales (Junior H, Linzae Lir)
Y la letra completa, claro.
Suno en plan Pro te da varias takes por prompt. Yo escuché 4-5, pedí 2-3 más con tweaks pequeños, y a la cuarta o quinta itera ya tenía la versión que me gustaba. Costo: dentro del plan Pro mensual ($8 USD), no creditos extra.
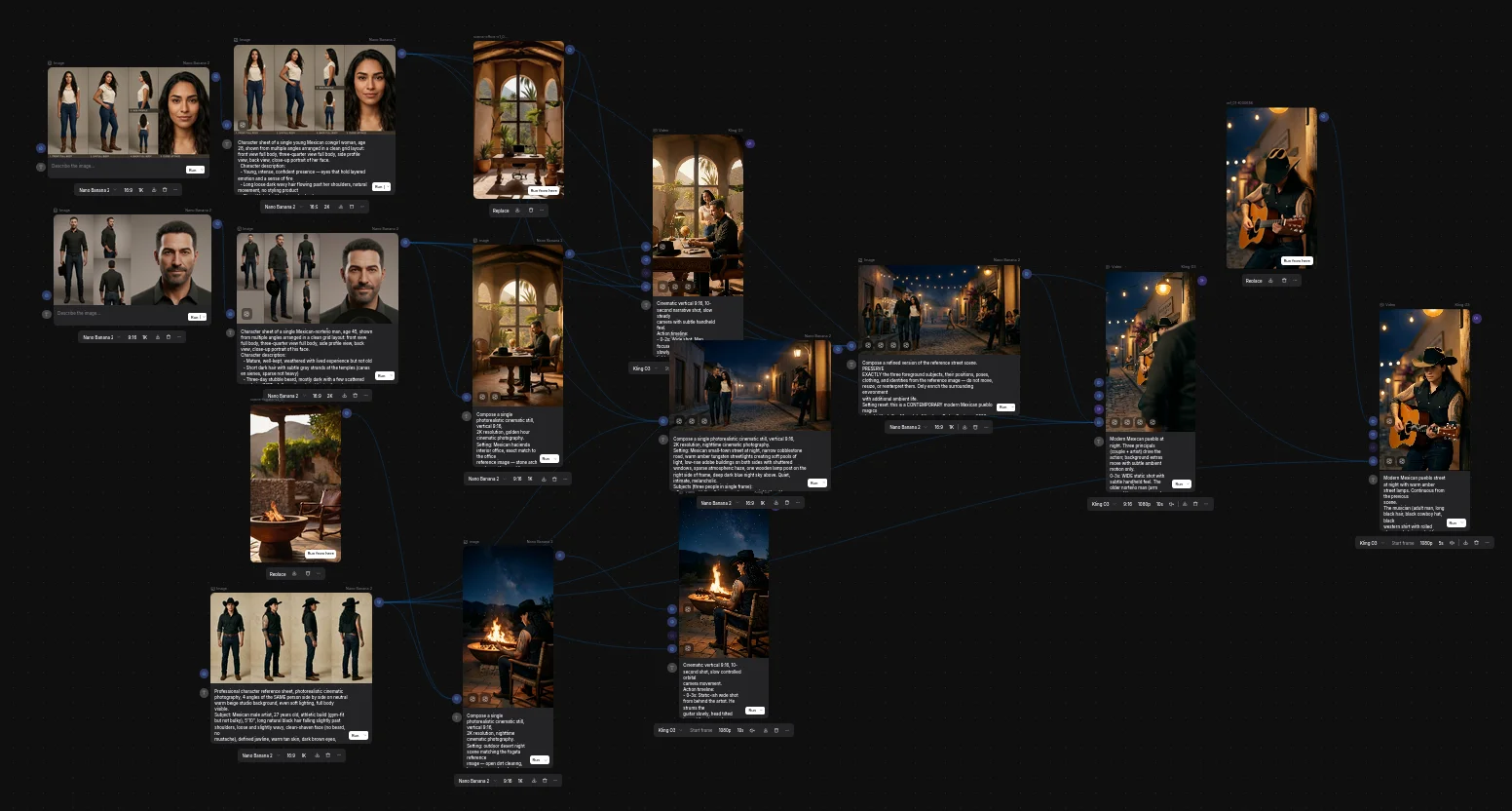
Paso 3: Personajes para el music video - el problema más caro
Aquí es donde se complica.
Quería un music video estilo cinematográfico - pareja madura en una hacienda mexicana, atmósfera de golden hour, más algunas escenas de un cantante anónimo de espaldas en una fogata. Necesitaba personajes consistentes - el mismo bato y la misma chica en múltiples clips, sin que cambien la cara ni la ropa entre escenas.
Problema: los modelos de imagen open-source actuales (SDXL local en ComfyUI) son malos para personajes fotorrealistas. Generan caras tipo cartoon 3D que no convencen. Los probé. Salen como Pixar. Inservible para cinemática realista.
Solución: Nano Banana 2 dentro de ElevenLabs Flows. Es de los mejores modelos de imagen ahorita para character consistency. Caro (~250-400 créditos por character sheet), pero las caras quedan fotorrealistas.
Generé tres character sheets (multi-ángulo, fondo neutro):
Hombre norteño 40-50 años, barba de 3 días con canas
Mujer cowgirl 25-35 años, pelo largo natural
Artista joven 25-30, pelo largo, sombrero negro, tatuajes
Costos reales:
Hombre: 251 créditos
Mujer: 406 créditos
Artista: ~300 créditos
Total character sheets: ~960 créditos
Estos sheets son assets reusables - los uso de referencia en TODAS las escenas futuras de Tlatol que tengan a estos personajes. Es inversión de una vez.
Paso 4: El pipeline de 2 pasos en ElevenLabs Flows
Aquí está el detalle técnico que casi nadie documenta:
Kling O3 (el modelo image-to-video) NO acepta múltiples imágenes de referencia + un prompt para generar video directo. Si quieres un clip donde aparezcan tu personaje A + personaje B + un escenario específico, tienes que hacerlo en 2 pasos:
Compose en Nano Banana 2 - le pasas las 3 imágenes de referencia (los 2 character sheets + el escenario) + un prompt describiendo la escena. Te genera UNA imagen still que une todo. Costo: ~1,500 créditos.
Image-to-video en Kling O3 - le pasas la imagen del paso 1 como start frame + un prompt describiendo el movimiento + los character sheets como omni-reference para mantener identidades. Costo: ~6,800 créditos por 9 segundos.
Total por clip: ~8,300 créditos.
Eso significa que un teaser de 30 segundos con 3-4 clips te cuesta entre 24,000 y 33,000 créditos.
El plan Starter de ElevenLabs te da 40K créditos al mes. Un teaser ya te lleva el 80% del tier. Por eso compré el add-on de $10 USD = otros 40K - para terminar el experimento sin estresarme con cada clip.
Paso 5: Los errores caros que cometí
Error 1: meter mucha acción narrativa en un solo clip
El primer clip que pedí era ambicioso: "pareja camina por la calle, pasan frente al artista, la chica voltea a verlo, el artista baja la guitarra, comienza a caminar, hace closeup, guiño, agacha la cabeza, sombrero le cubre la cara".
Eso son 8 acciones secuenciales en 9 segundos. Kling no las puede manejar todas juntas - se le van las identidades, salta acciones, hace transiciones raras. Resultado: 6,800 créditos quemados en un clip que no usé.
Lección: máximo 2-3 acciones por clip de Kling. Movimiento de cámara explícito. No encadenar acciones complejas.
Error 2: prompts genéricos sin dirección de cámara
Mi primer clip atmosférico fue "subtle motion on cowboy at dawn". Salió plano, sin alma. Kling no sabía qué seguir, tiraba motion ambiental aleatorio.
Lección: todo prompt de Kling necesita "camera dollies in on X as Y happens". Sujeto explícito + acción + dirección de cámara.
Error 3: pelearme con el safety filter
Un prompt que me rechazó incluía: "young artist, hat brim fully covering his face, exact identity from reference, MUST match exactly". Filter rejection.
El patrón que el filter detecta: identidad específica + cara oculta + énfasis paranoid en mayúsculas. Suena a deepfake prompt para un sistema automatizado.
Lección: evitar palabras como "fully covered", "obscured", "exact identity in caps". Reemplazar por "casting cinematic shadow", "matching the character reference". Sin mayúsculas dramáticas. Sin "young" + "hidden face" combinados.
Paso 6: Edit final - Kdenlive sí, DaVinci no
Pensé en DaVinci Resolve (es el estándar). Mala decisión en Linux:
DaVinci Resolve Free en Linux NO soporta H.264 ni AAC nativamente (licencias propietarias). Tus clips de Kling salen H.264. Al importarlos: video gris/negro, sin audio.
Workaround: transcodear cada clip a DNxHR antes de importar. Cada cambio = re-transcode. Insufrible.
Cambié a Kdenlive (open source, repo oficial Arch):
sudo pacman -S kdenliveSoporta H.264/AAC nativo. Importa los mp4 de Kling directo, sin transcode. Soporta SRT para overlay de letras. Tiene Pan & Zoom (Ken Burns) para imágenes estáticas. Suficiente pa' un teaser vertical 9:16.
Paso 7: Distribución y disclosure
Subí el teaser a:
TikTok (la plataforma principal)
Instagram Reels (mismo mp4, hashtags ligeramente distintos)
Facebook Reels
Hashtags que usé en TikTok (mezcla de niveles):
#mientrasmemientas #tumbadoromantico #corridostumbados
#musicamexicana #desamor #amorprohibido
#sunoai #musicaai #aimusic
#nuevamusica #parati #fypImportante: disclosure de AI. TikTok ya penaliza contenido AI sin disclosure desde 2024. Mejor declararlo (#sunoai #aimusic) y aprovechar la curiosidad de la audiencia AI, que esconderlo y arriesgar el shadowban.
El framework de medición que me forcé a respetar
Escalación gradual basada en señales del mercado:
Views a 7 días | Acción |
|---|---|
<100 | Re-evaluar concepto. NO invertir más. |
100-500 | Continuar al ritmo actual |
500-2K | Acelerar producción de clips |
2K-10K | Upgrade ElevenLabs Creator ($22/mo, 100K creds) |
Ventana de medición: 30 días desde el primer teaser. Decisión a día 30: pegó o no pegó.
Stop-loss declarado para mí mismo: no más dinero hasta ver señal. No comprar add-ons aspiracionales. No upgrade de tier basado en momentum. Data primero, dinero después.
Lo que NO recomiendo
Listar AI como co-author - no se puede legalmente en ningún país. Y romper la solicitud de registro por moralismo es bobo.
Comprar add-ons aspiracionales - "voy a comprar 100K créditos por si acaso necesito hacer 10 teasers". No. Compra cuando midas que se necesita.
Escalar tier antes de medir - el tier Creator ($22) tiene más sentido que el Starter + add-ons SÓLO si vas a usar 100K créditos al mes consistente. Si todavía no sabes, quédate en Starter.
Producir el music video completo antes del primer teaser - si nadie engagea con el teaser, el music video completo lo ves tú y nadie más. Teasers primero, full video si pega.
Saltarte la ingeniería inversa - el análisis técnico de referencias toma 5 minutos y mejora drásticamente lo que Suno te entrega.
Sobre el uso de AI
Tlatol es transparente sobre el uso de AI. Está en los hashtags, está en este post, va a estar en la bio de las cuentas. La rola es legítima - escribí la letra, dirigí el estilo, escogí los takes, dirigí los clips, ensamblé el edit final. Hay autoría humana en cada decisión. Pero la herramienta es AI, y eso no se esconde.
La gente que vibra con la rola la va a vibrar con o sin disclosure. La gente que se ofende con AI music probablemente no era audiencia de tumbados de todas formas. Y el algoritmo de TikTok premia la transparencia desde 2024.
¿Y ahora?
Ventana de 30 días para medir. Cada 7 días reviso views, comments, follows orgánicos contra los triggers numéricos. Día 30: GO/NO-GO formal.
Si pega -> siguiente rola con mejor pipeline (cinemagraphs en lugar de Kling clips, ahorra 50% de créditos), upgrade a Creator, music video completo, DistroKid a Spotify.
Si no pega -> re-evaluar concepto, posiblemente pivotear al sub-género tumbado fifi (audiencia distinta, puede pegar mejor), o cambiar la fórmula completa.
Lo que sí: aprender en público. Cuando llegue el día 30, regreso a este blog con los datos reales. Con números, no con copium.
Mientras tanto, si quieres oír la rola: está en TikTok como @tlatol.com. La rola se llama "Mientras me mientas". Tumbado romántico. Voz masculina. Si te late, dale like - eso ayuda más al algoritmo de lo que crees.